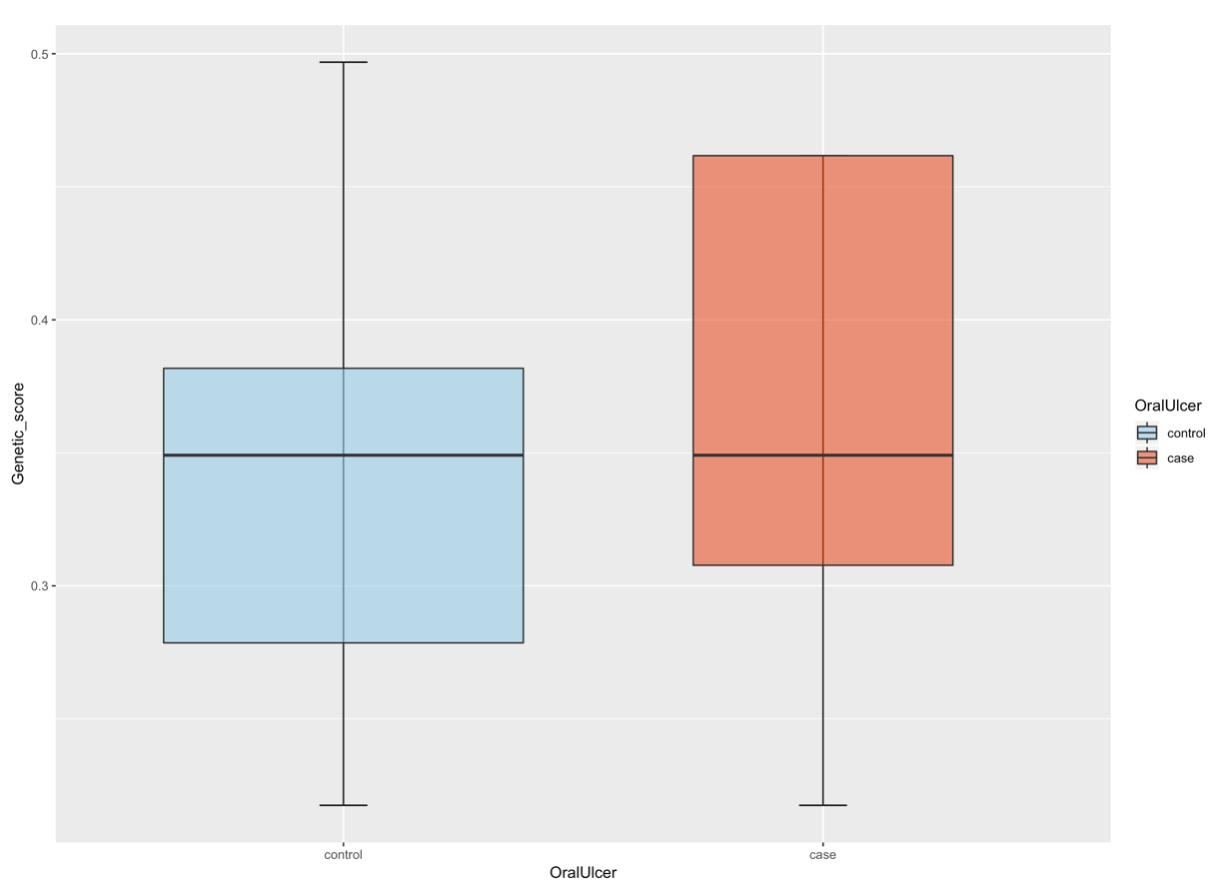
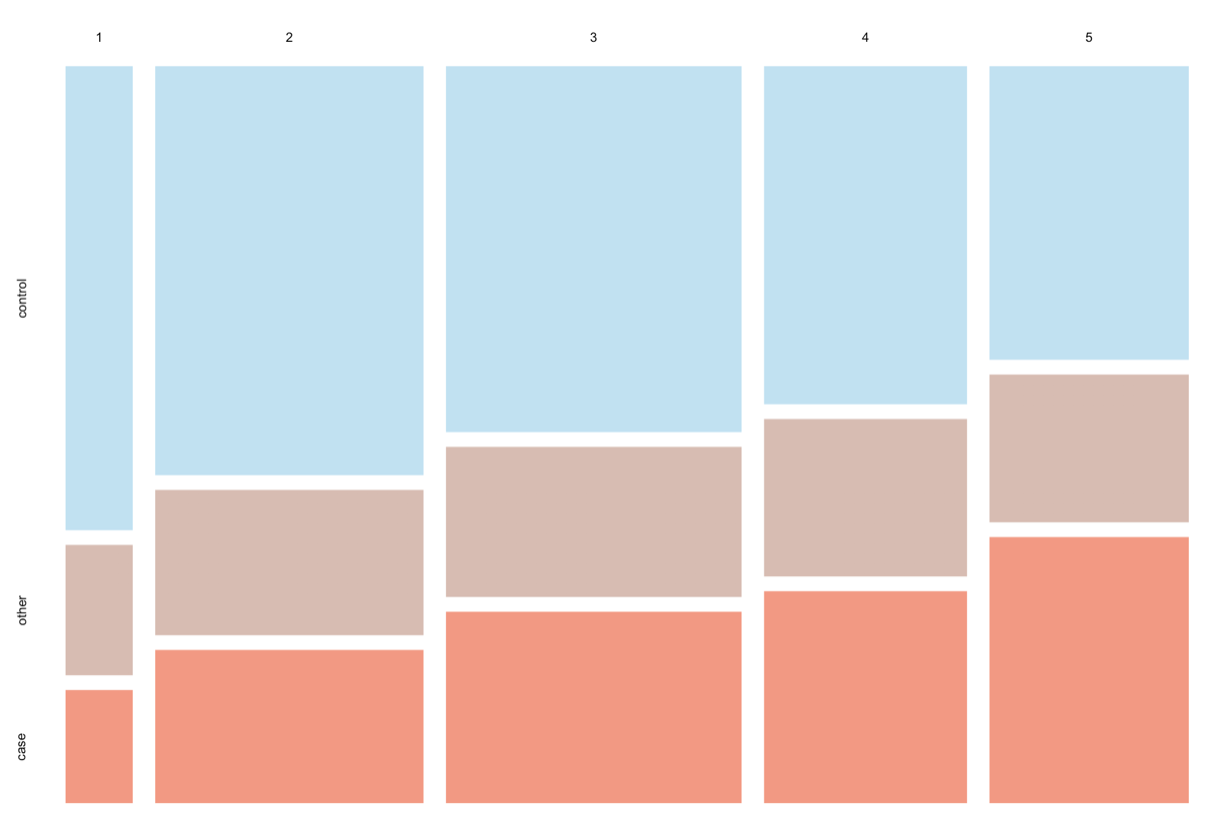
口腔溃疡易感性
口腔溃疡在临床上被称作「复发性阿弗他口炎」,是一种最常见的口腔黏膜疾病。该疾病的特征是反复出现一至多个疼痛性溃疡,虽然溃疡常在 7~14 天内愈合,但却对患者的生活造成影响。
目前的研究认为,遗传因素、营养缺乏、病毒和细菌感染以及免疫失调或内分泌失调都是可能导致口腔溃疡的危险因素。
检测结果
通过预测模型计算出 5 组基因结果,分段长度代表每组结果的人群占比。
Lv.1
Lv.2
Lv.3
Lv.4
Lv.5
可能性低可能性高
口腔溃疡易感性高
口腔溃疡的相关发现
根据23魔方的研究数据发现,口腔溃疡的发生可能与以下因素有关。

吸烟对口腔溃疡的影响
相比不吸烟的群体,吸烟群体中容易发生口腔溃疡的人更少。
但据研究报道,只有摄入足够多的尼古丁,才可能有减少口腔溃疡发生的作用。这是因为过多的尼古丁在口腔黏膜上形成了一层角蛋白,从而起到了保护作用。* 需要注意的是,吸烟对已经存在的溃疡并没有保护作用。
* 该结果来自于23魔方研究所,仅基于23魔方的用户样本。

压力对口腔溃疡的影响
我们的研究还发现,情绪、压力等也会影响口腔溃疡的发生。在情绪经常变化或常感到有压力的人群中,容易发生口腔溃疡的人更多。* 该结果来自于23魔方研究所,仅基于23魔方的用户样本。

口腔溃疡和其他疾病
需要注意的是,一些疾病也可能会导致口腔溃疡发生,例如白塞氏病,马歇尔综合症(PFAPA 综合症)等,因此在口腔溃疡反复发作的时候,需要就医排除是否有其他疾病发生。
如何预防口腔溃疡
目前对口腔溃疡的病因和发病机制还不够明确,因此没有明确的能够预防口腔溃疡发生的方法,但以下几种行为或许能帮助你减少口腔溃疡的触发。